Your greatest inheritance since that rich uncle died
In this post, we explore the world of Google Cloud Platform (GCP) IAM and how to navigate your way through it. Out of the three major cloud providers (AWS, Azure, and GCP), Google’s approach to Identity and Access Management is the most straightforward. However, its relative simplicity can lead to some pitfalls, which we explore here.
The GCP Hierarchy
In contrast to AWS and Microsoft Azure, permissions in GCP aren’t assigned via a central service. Instead, permissions can be given at any “level” of the resource structure, and they apply to any resource lower down the hierarchy. So, first, let’s take a look at the hierarchical structure of resources in Google Cloud Platform.
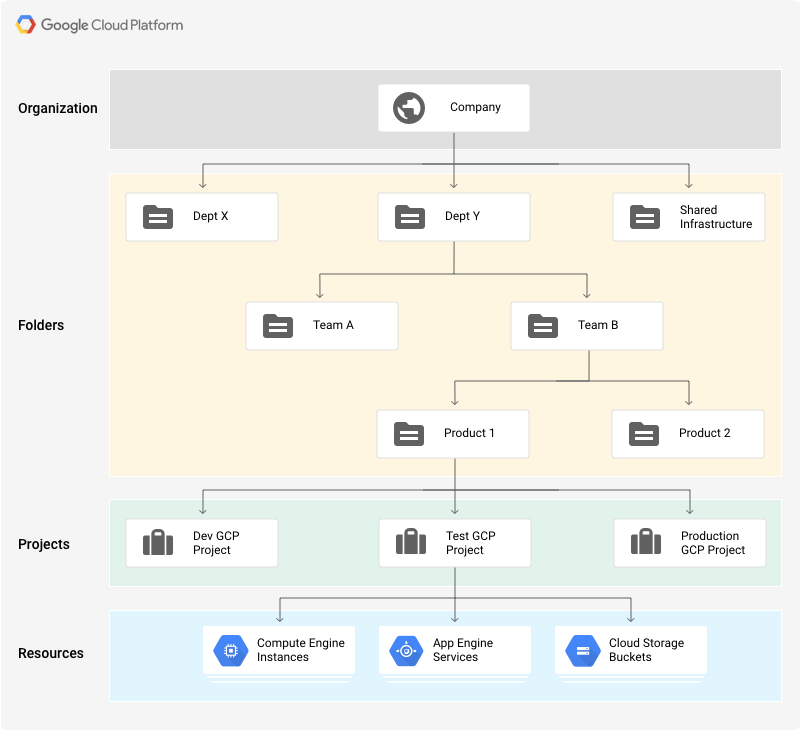
At the top of the pyramid is the Organization — an entity that represents a company, for example, and under which all resources reside. An organization is closely related to your Google Workspace (previously known as G Suite) Account, allowing companies to manage projects centrally and to maintain ownership of projects even after the account of the user who created them is closed. Any permission that is given to an entity at the organization level will apply to any and all resources that exist under this organization.
Folders are a type of resource that allows you to divide your organization into logical units. Folders are the first method to create boundaries between different resources in the organization. For example, you can create different folders for your legal branch, development branch, and sales department. Each folder can then contain other folders, each representing different teams, for example. This allows you to define a type of super-user that has permissions across different teams but not branches.
One level below folders, we get to the base entity you may be familiar with as a private user of GCP — the Project. A project contains all compute, data, and storage services you would use on a day-to-day basis for your applications, such as your Google Kubernetes Engine applications, BigQuery databases, and Compute Virtual Machines. These individual resources and services are, then, at the bottom of the pyramid.
Unto Whom the Permission Applies
As you may already know, IAM policies are all about who can perform what actions on which resources. The previous section discussed “which resources,” so now let’s discuss the who.
- User
Users are the most basic type of member. These can be any Google account, including a regular gmail.com user account or even a Google domain account. - Service account
A service account is used to allow your applications to interact with the different resources and APIs in GCP. These are created under your different projects, and you can create as many as you need to represent different levels of access. - Group
Google groups represent a collection of users. You can grant permissions to these groups, identified by a single email address, and all members of this group will inherit these permissions. It’s a great way to make the management of user permissions much more convenient and easy to audit. - Google domains
Google Workspace and Cloud Identity domains, in the context of IAM members, represent all the accounts which are created under that domain. For example, if you grant permissions to the acme.com domain, any user (such as bob@acme.com) will inherit those permissions. - AllUsers
Grants permissions to everyone. Literally everyone. - AllAuthenticatedUsers
Very much the same as AllUsers, but users must be logged in (authenticated) to their Google account.
The What!
Finally, let’s discuss how to grant permissions in GCP and what those permissions represent.
Each permission in GCP can generally be broken down into three parts: service, resource, and verb. For example, compute.instances.start represents the permission to start (i.e., turn on) instances (virtual machines) in GCP’s compute service.
In the vast majority of cases, IAM permissions correspond to an API endpoint. For our example, it would correspond to the endpoint:
https://compute.googleapis.com/compute/v1/projects/{project}/zones/{zone}/instances/{resourceId}/start
Roles are simply a collection of permissions. In GCP, you cannot grant permissions directly to members. As most actions require multiple permissions, it’s simpler to group those permissions into Roles, and then grant (bind) those roles to the entity you want to grant permissions to.
Roles come in three different types: Basic (also known as Primitive), Predefined, and Custom.
Basic roles predate what we know as IAM in GCP today. They come in Owner, Editor, and Viewer flavors. As their names suggest, the Owner role has full control over the project. They are able to view, edit, and create all resources. The Editor role can view and modify all resources but not create any new ones. The Viewer role has read-only permissions. It is considered best practice to avoid using these Primitive roles. Their permissions are very broad, and they are not scoped to any services or resources, so they generally fall outside the principle of least privilege.
Predefined Roles, on the other hand, are a bit more granular. They are set up and maintained by GCP, and allow you to have better control over which services and functions a user is allowed to invoke. For example, the Cloud SQL Viewer role allows read-only access to your Cloud SQL instances. It contains the 20-odd permissions a user needs to retrieve data from a database, and no more.
If you find that you need even more control and finer granularity, you can always create your own Custom Role. You can pick and choose exactly which permissions are grouped into that role to tailor them for your specific needs.

Putting It All Together
Now that you have your Who, What, and Where, it’s time to put it all together into a Policy. Policies are simply a list of bindings of Roles and Members. They can be defined at almost all of the levels of the resource hierarchy we’ve discussed above. At whatever level you choose to define your policy, all of those descending will also inherit those policies.
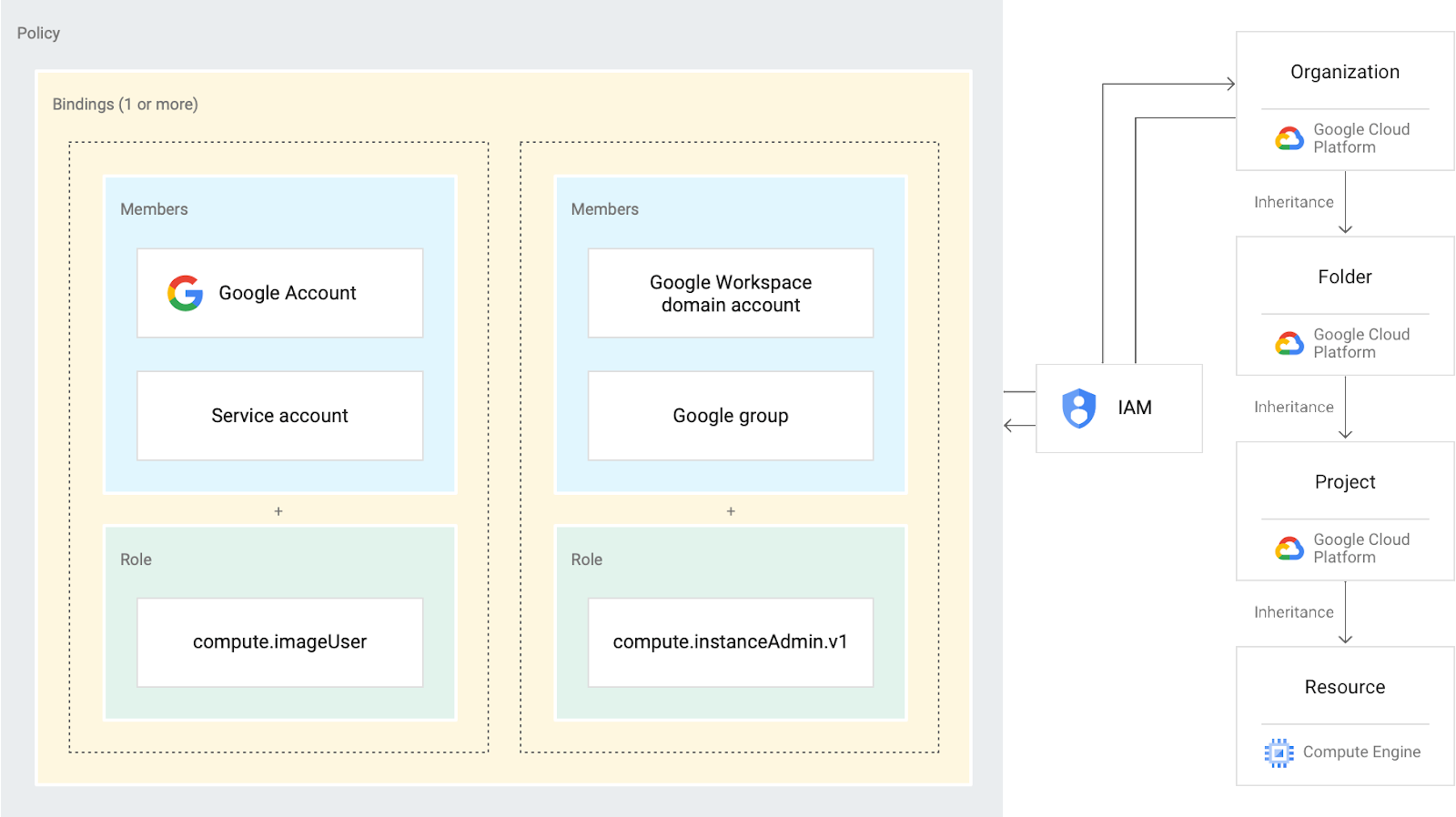
Note that this means that you cannot revoke permissions given at a parent node in the hierarchy. For example, user Alice was given the Storage Object Editor role at the project level, granting her the ability to view and modify any objects in any storage bucket contained in this project. If we then grant her the Storage Object Viewer role for a specific bucket, it would not impede her ability to also modify any objects in that bucket. That is due to permission inheritance.
Bottom Line
As you can see, the GCP approach to identity and access management is straightforward. Choose the scope for which you want permissions to apply, create a policy attaching different Roles to specific Members, and you’re done! The most important part, then, is that you choose the scope carefully, and apply the policy in the correct place, as all children of a node are always within their parent’s scope.
In a future post, we’ll talk about common Google Cloud Platform security mistakes and misconfigurations , best practices, and privilege escalation attacks that can lead to a simple user with minimal permissions becoming an Owner of a project. Stay tuned!
Google Cloud IAM FAQ
What roles are available on Google Cloud IAM?
Google Cloud identity access management (IAM) supports three kinds of roles: basic, predefined, and custom. The basic (aka primitive) roles are legacies from before IAM was introduced. They include the generic owner, editor, and viewer roles; These should generally be avoided as they encompass thousands of permissions across all GCP services.
Predefined roles are more fine-grained. They let you precisely specify which res a user can access and what operations they can perform. For example, the Log Viewer role only gives access to view logs – nothing more.
If you can’t find a role that matches your exact requirements, you can create a custom one by selecting one or more permissions.
Where can I find Google Cloud IAM best practices?
The Use cases section in Google’s Identity and Access Management documentation has multiple guides for IAM best practices and recommendations.
- The Using re hierarchy for access control guide shares best practices for determining IAM configurations at each re hierarchy level: organization, project, and re.
- The Using IAM securely guide provides recommendations regarding least privilege, service account management, auditing, and policy management.
- The Understanding service accounts guide offers detailed information about service accounts, such as granting access to a service account, identifying unused service accounts, and setting permissions for service accounts.
- Other available guides list recommendations for more specific use cases, such as IAM roles for auditing-related job functions and Best practices for using workload identity federation.
Where can I find Google Cloud IAM Conditions documentation/tutorials?
Google Cloud IAM documentation includes an Overview of IAM Conditions page, which describes this feature in detail. You can read about the common expression language (CEL) used to create a Condition expression. And you can also find information about Condition attributes and a list of re types that support conditional role bindings. Throughout there are sample configuration snippets that illustrate syntax and use of IAM Conditions.
How do Google Cloud IAM logs and logging work?
Like every other GCP service, IAM produces audit logs that record who did what, where, and when. The two main IAM audit log types address Admin Activity and Data Access. Admin Activity audit logs contain entries for operations that change re configuration or metadata; these cannot be disabled.
Data Access audit logs record all operations that read the configuration and metadata of res, along with any read/write operations on user-provided data. These logs are only produced if they’re explicitly enabled.
To learn which API operation matches which audit log type, refer to the table on the GCP IAM audit logging webpage. It includes information about audit log format, enabling audit logs, and setting permissions for logging.