
The fundamental principle of scanning artifacts at build time is, if I can fix a security issue before it’s ever deployed, I’ll reduce my attack surface before it ever exists and I’ll free up security teams to focus on more important and emergent threats (such as vulnerabilities that are found after the application is deployed).
Orca’s container image scanning allows you to do exactly this for your container image pipelines; however, this still potentially allows for secrets and vulnerabilities to be built into the app and pushed to artifact repositories like a container registry. From there, it’s possible that it might be accessed by an attacker to scrape out the secrets embedded or accidentally deployed from there. Finding these issues at build time is preferable to finding them at runtime but orgs would be more efficient if they could start finding these problems earlier.
Orca’s newly-released file system scanning capabilities do just this, allowing you to find secrets and vulnerabilities in packages used in source code well before the code is even built and shipped. This enables you to implement a complete approach to finding these issues that starts when code is pushed to a code repository, continues through scanning after build, and, finally, continues to monitor apps when they’ve moved to testing and production.
As with all of Orca’s shift-left scanning, you can centrally manage policies to ensure that what’s applied in the scan matches organizational priorities. Secrets scanning includes 170 different types of secrets that might be found in code today and vulnerability scanning will find vulnerable packages in Ruby, Python, PHP, Node.js, .NET, Java, and Golang. Policies can be set to “warn only” or to fail a scan at particular severity thresholds – some orgs will want to explicitly block particular issues at an early stage while other orgs want to notify without inhibiting a developer at an early stage. Flexible policies allow you to address a wide variety of requirements.
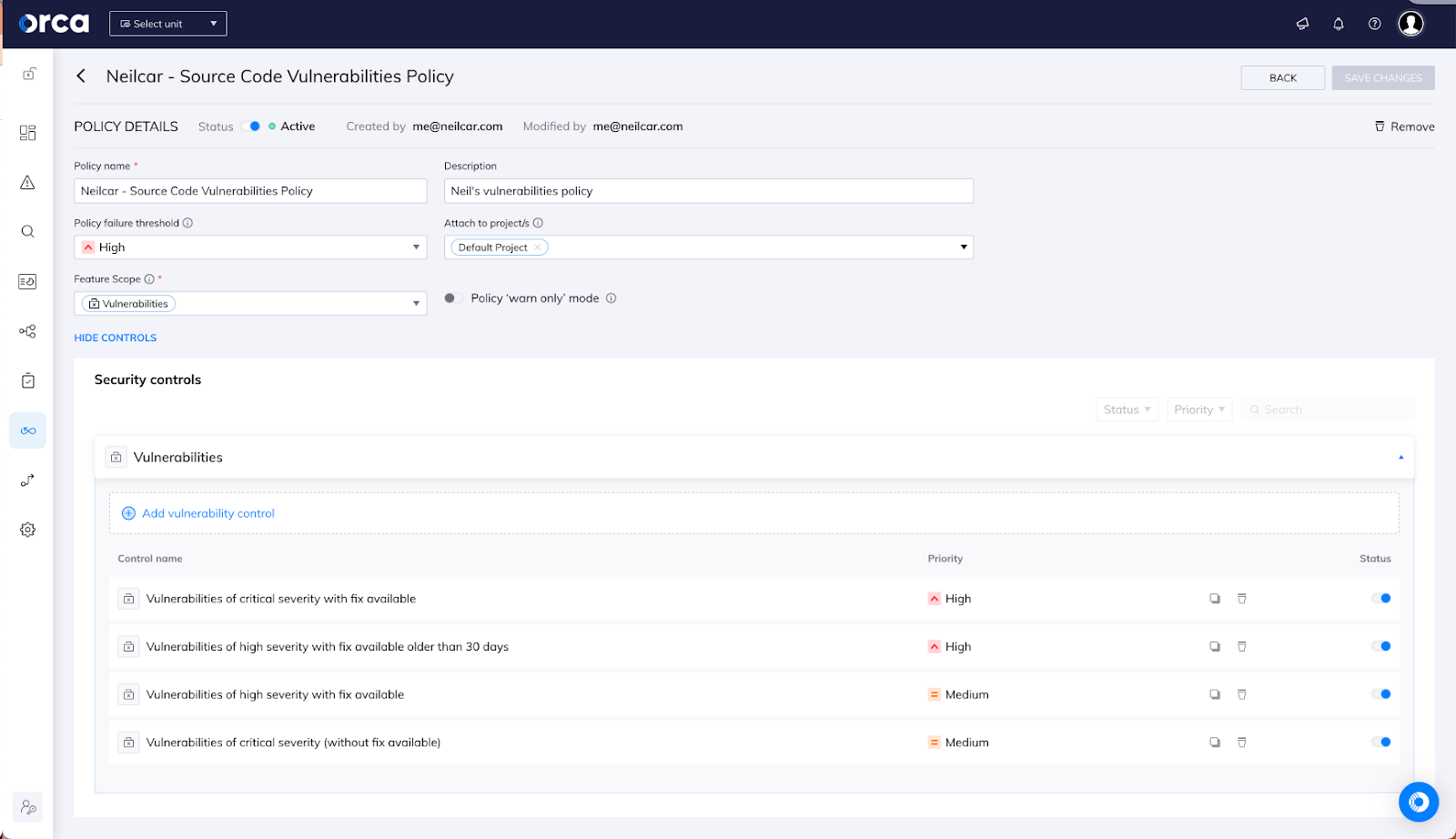
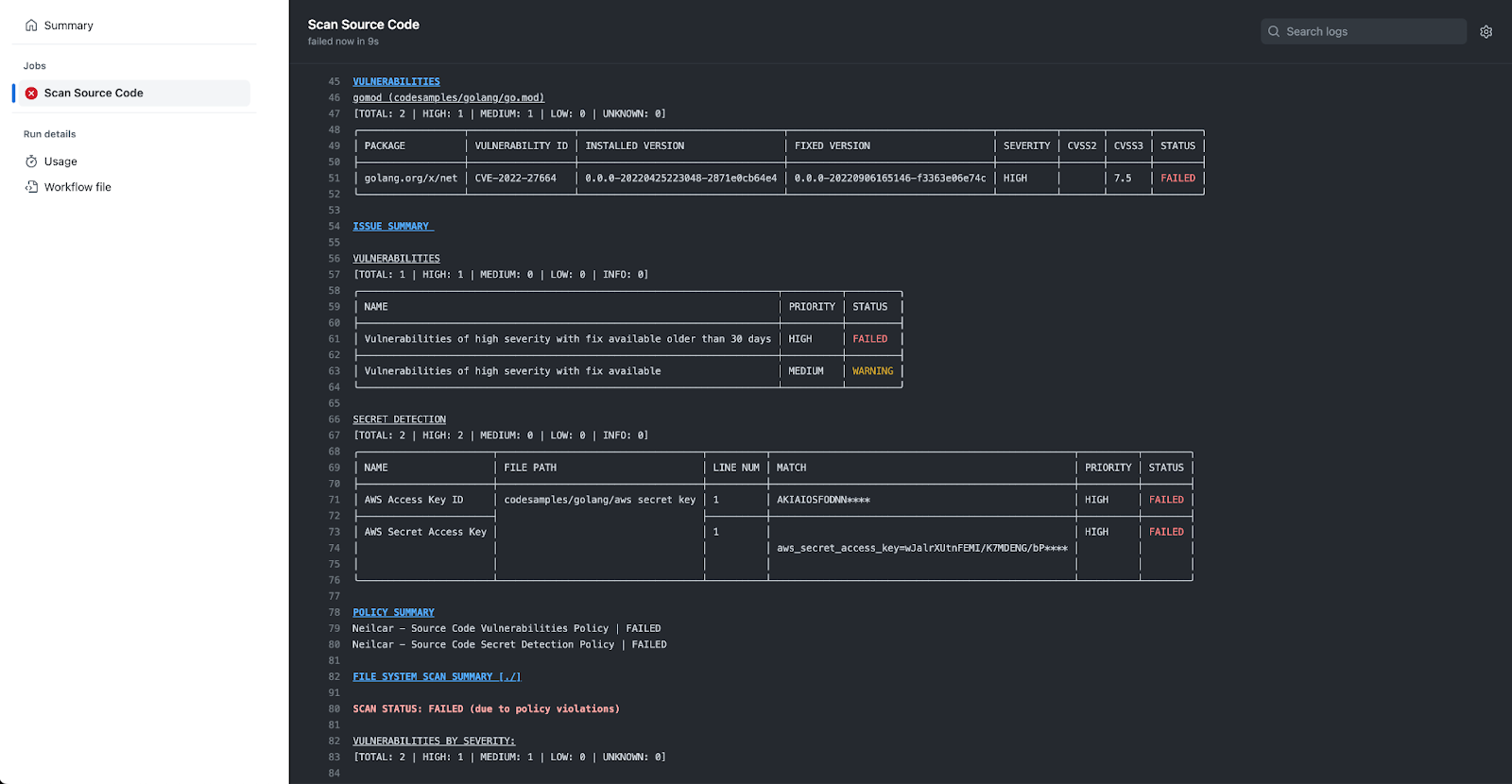
With my centralized policies set, the next step is to integrate this into wherever I want to scan my code. My projects live in GitHub; however, since this is all accomplished with a lightweight CLI tool, it’s very easy to add this wherever my developers are working. I’ve added a GitHub action to my repo that kicks off a scan whenever I push something new or create a pull request and, on my next push, I can see that I have a few significant problems to clean up before I build this project:
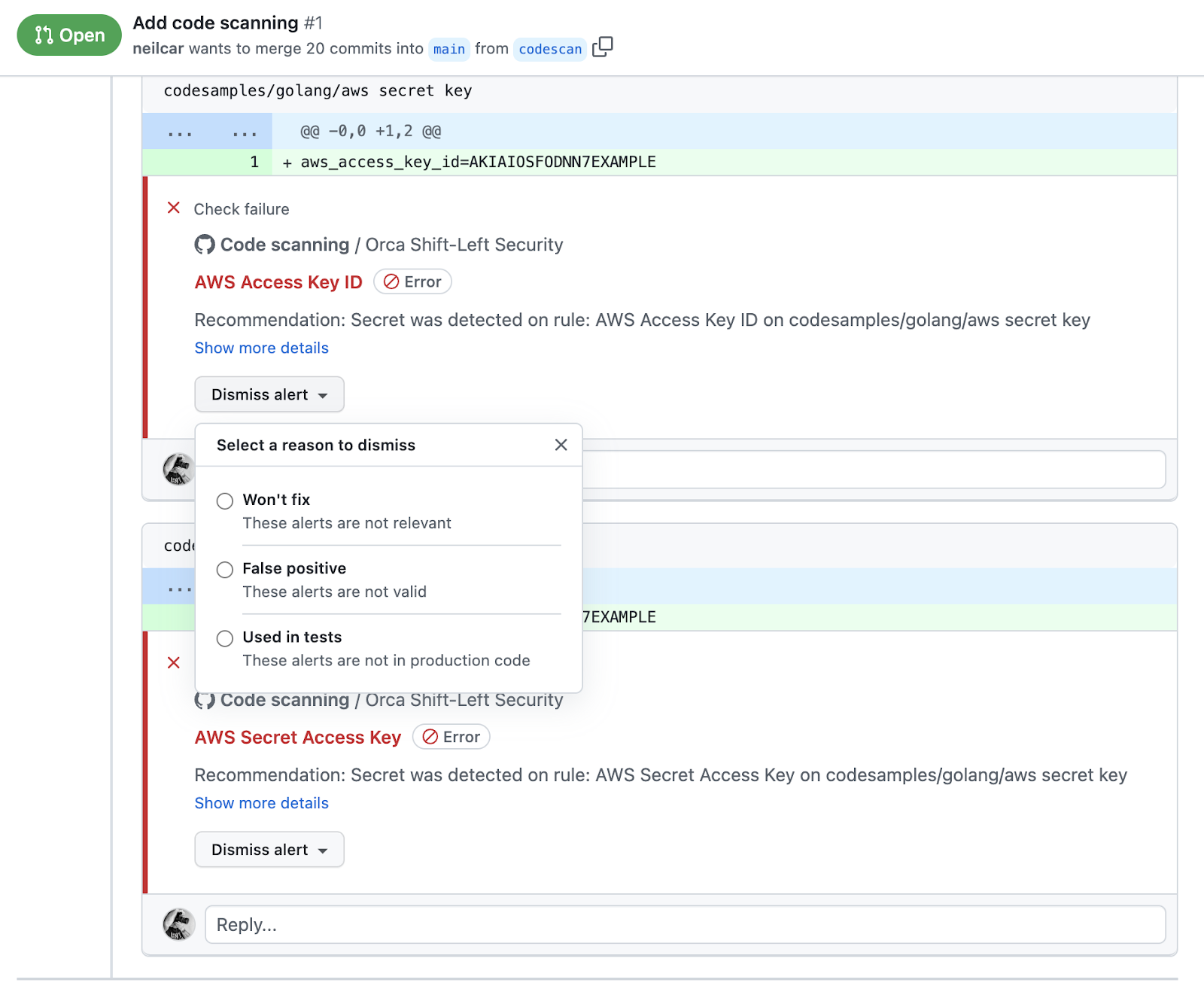
If I use the GitHub Action for integration, I can also see annotations directly inline. For example, I can see directly in my pull request precisely where I’ve introduced a secret and I can directly manage the alert – that is clearly a sample access key that I am, in fact, using in tests. This is a real improvement in efficiency because we can put security findings & policy violations directly in front of developers where they’re already looking.
My security team can also see a centralized log of all the scans, providing global visibility of the results from different repositories and pipelines across my entire organization.
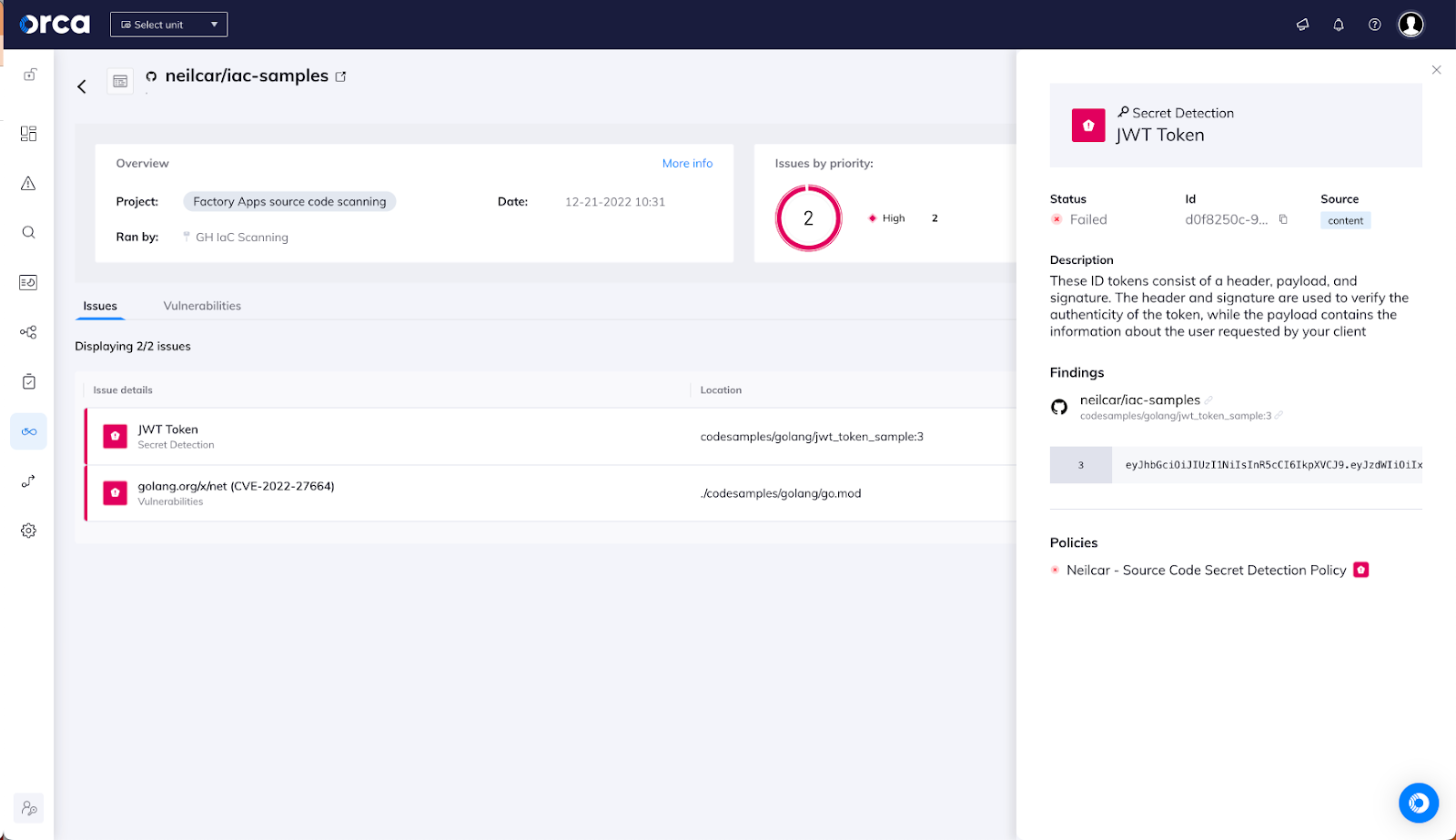
With this integration, I’m able to find where I’ve accidentally checked in a secret I was using or where I’ve included a vulnerable version of a library in my code. With this visibility, I can fix those problems before they even end up built into a container image or deployed to a cloud account (or anywhere else).
Conclusion
These new Shift Left Security capabilities are available in the Orca Platform today. To learn more, start a 30-day free risk assessment or view our recorded demo.





