The cloud environment relies on a few core principles. One of them is the idea that each customer is isolated from other customers, and no data can be inadvertently accessed across accounts. As the Internet moves more and more to the cloud, the importance of cloud security becomes increasingly paramount.
We, the Orca Security Research Team, discovered a critical security issue in the AWS Glue service that could allow an actor to create resources and access data of other AWS Glue customers. The exploit was a complex multi-step process and was ultimately possible due to an internal misconfiguration within AWS Glue. The Glue service has access to large quantities of data, making it a highly attractive target.
We’re sharing this with you today after having worked with AWS to remediate the issue and confirm with AWS that no customer accounts were inappropriately accessed. Within hours of reporting the issue, the AWS Glue service team had reproduced and confirmed our findings. By the following morning, a partial mitigation was deployed globally, followed by a full mitigation a few days later.
AWS Principal Engineer, Anthony Virtuoso had this to say about our joint collaborative efforts in discovering and quickly fixing this vulnerability:
“At AWS, security is everyone’s job and our highest priority. We take vulnerability reports extremely seriously. We spend a lot of time thinking about and implementing security invariants to keep our customers safe, and we appreciate when that work can be informed or improved by independent security research.”
Anthony continued, “Today, Orca Security, a valued AWS partner, helped us detect and mitigate a misconfiguration before it could impact any customers. We greatly appreciate their talent and vigilance, and we would like to thank them for the shared passion of protecting AWS customers through their findings.”
Technical Overview of the Superglue Zero-Day Vulnerability
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. During our research, we were able to identify a feature in AWS Glue that could be exploited to obtain credentials to a role within the AWS service’s own account, which provided us full access to the internal service API. In combination with an internal misconfiguration in the Glue internal service API, we were able to further escalate privileges within the account to the point where we had unrestricted access to all resources for the service in the region, including full administrative privileges.
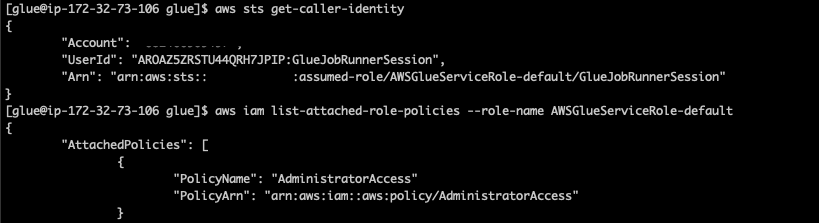
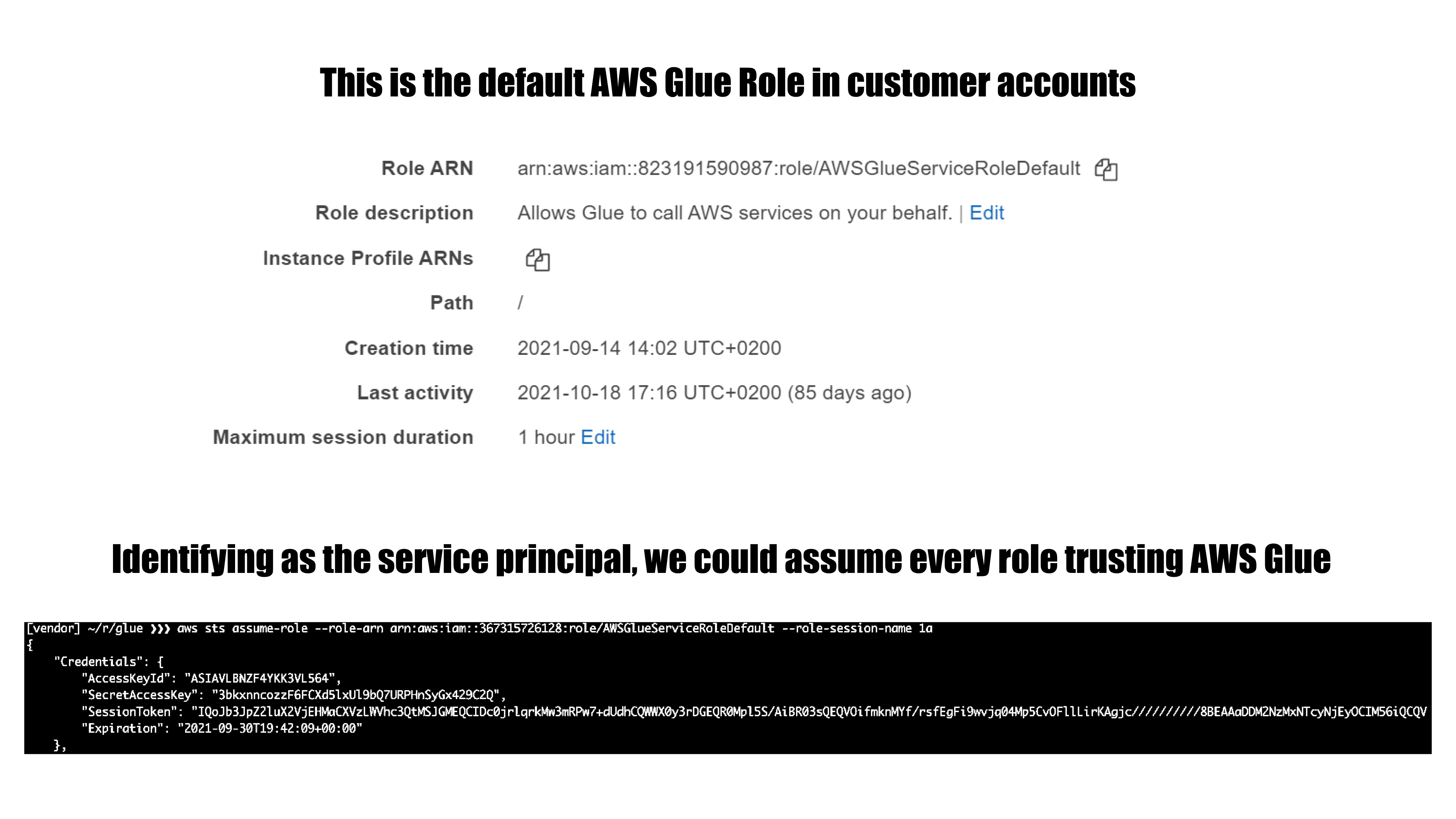
By carefully looking at what data could be accessible in the service account, we confirmed that we would be able to access data owned by other AWS Glue customers. We used accounts under our control to test and verify that this issue gave us the ability to access data from our other accounts without affecting any other AWS customers’ data.
These are some of the things that we were able to do:
- Assume roles in AWS customer accounts that are trusted by the Glue service. In every account that uses Glue, there’s at least one role of this kind.
- Query and modify AWS Glue service-related resources in a region. This includes but is not limited to metadata for: Glue jobs, dev endpoints, workflows, crawlers and triggers.
As mentioned above, all research related to this finding was conducted within AWS accounts owned by Orca Security. No other AWS customer accounts and no other customers’ data was accessed during our research.
We would like to thank the AWS security team, specifically Dan Urson and Zack Glick, for collaborating with us and working to quickly confirm and resolve this issue. The process of reporting and having the issue resolved was smooth and we got to meet some of the great people at AWS that help make sure the cloud is secure.
The Orca Security Research Team continues to dig around different cloud products and services to find such zero-day vulnerabilities. Our goal is to discover these vulnerabilities before any malicious actors do.
If you’d like to learn more about Orca Security I invite you to experience our tech and talent first-hand with a no-obligation, free cloud risk assessment. You’ll get complete visibility into your public cloud, a detailed risk report with an executive summary, and time with our cloud security experts.

Discover Your Cloud Vulnerabilities In Minutes
Scan your entire AWS, Azure, and Google Cloud environments for vulnerabilities with Orca Security’s free, no obligation risk assessment.
AWS Glue FAQ
What is AWS Glue, and what is a Glue job?
AWS Glue is a serverless integration service that simplifies the discovery, categorization, preparation, and aggregation of data. It offers both graphical and code-based interfaces to perform all the usual data integration tasks, including:
- Multi- data cataloging and extraction using AWS Glue Data Catalog.
- Data cleaning, normalization, and combination using AWS Glue DataBrew.
- Building, testing, running, and monitoring ETL (extract, transform, and load) workflows using AWS Glue Studio.
- Creating views that aggregate and replicate data across data stores using AWS Glue Elastic Views.
A Glue job defines business logic used to extract data, process it, then store it to the specified location. You can either have AWS Glue generate a job for you or upload your own. Jobs can run both ETL and Python scripts.
Why use AWS Glue?
There are several benefits of using AWS Glue:
- Being serverless, you don’t have to provision or manage infrastructure. It scales up or down as required.
- It fast-tracks data integration and gets you set up in minutes instead of months.
- Glue minimizes the need to write ETL code. Developers and data engineers can use the visual interface(s) to perform and automate most tasks.
- It works with both structured and unstructured data.
- Glue can detect schema changes and adapt based on the configuration.
- It lets you catalog data stored in Amazon Simple Storage Service (S3) and run SQL queries on it using Amazon Redshift Spectrum and Amazon Athena.
- Glue generates real-time metrics to monitor performance and operations of your data warehouse/lake.
- It enables you to transform semi-structured data into relational tables.
What should I use AWS Glue for? How does it work?
Some AWS Glue use cases are:
- Build highly performant, fault-tolerant ETL pipelines without writing code.
- Create event-driven ETL pipelines by calling your Glue job inside an AWS Lambda function.
- Quickly extract data from multiple s, clean it on an intuitive visual interface, then aggregate and load it to your data warehouse/lake.
- AWS Glue Data Catalog enables you to catalog data spread across multiple AWS assets, including Amazon Simple Storage Service (S3) and Amazon Redshift. You can then use Amazon EMR or Amazon Athena to run queries on the cataloged data.
- Use AWS Glue DataBrew to experiment with data stored in your data warehouses, lakes, and databases, including Amazon RDS, Amazon S3, and Amazon Aurora. Select from over 250 built-in transformations to prepare data without having to write any code.
- Create materialized views across multiple databases and data stores using AWS Glue Elastic Views.
- Transform semi-structured data to relational tables.
What is the AWS Glue crawler?
AWS Glue crawlers are used to scan data from repositories and perform the following actions:
- Classify data to discover its format and schema
- Divide data into tables or partitions using crawler heuristics
- Store metadata in the AWS Glue Data Catalog
You can create a crawler using the AWS Glue console or the AWS Glue API. Several configuration options let you customize crawler behavior. For example, you can configure what one should do when it detects a schema change. Read more about crawler configuration options here.
If you’re crawling data to create metadata tables in the AWS Glue Data Catalog, you should specify one or more classifiers. These are used to assess data format and determine schema. You can either choose from a set of built-in classifiers or create a custom one.
Crawlers support several databases, including Amazon Simple Storage Service (S3), Amazon DynamoDB, Delta Lake, Amazon Redshift, MariaDB, MySQL, and Oracle.
What is the AWS Glue Data Catalog, and where is it stored?
AWS Glue Data Catalog is a primary component of the AWS Glue service that persists and annotates metadata. It stores references to all data used as s or targets of your AWS Glue jobs. It’s a unified repository where disparate system metadata is stored and used to query and process data.
The catalog is composed of databases and tables. A database is used to organize and categorize metadata tables. A table can only be in one database, and there is a separate metadata table for every data store. A database can contain tables representing metadata of several data stores.
Crawlers are usually used to fetch and store metadata, but there are other ways of doing so. For example, you can use the AWS Glue console to manually create a metadata table. Or you can use AWS CloudFormation templates.
Other AWS services also use the AWS Glue Data Catalog, including Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum.
Is AWS Glue HIPAA-compliant?
Yes, Glue falls within the scope of the HIPAA compliance program of AWS. Multiple features protect sensitive data, both at rest and in transit, and securely execute workloads containing protected health information (PHI).
However, it’s each client’s responsibility to apply these features depending on data sensitivity, applicable regulations, and compliance needs. For example, if you’re processing healthcare data and aspire to be HIPAA compliant, you must enable the following features:
- Secure JDBC connections to data stores using SSL/TLS
- Pass the server-side encryption (SS3-S3) configuration as a parameter to AWS Glue jobs
- Ensure encryption is enabled when creating a data catalog object. This will encrypt all metadata stored inside the AWS Glue data catalog.
Refer to this AWS whitepaper to learn more about architecting for HIPAA security and compliance.
Yanir Tsarimi is a Cloud Security Researcher at Orca Security. Follow him on Twitter @Yanir_